https://arxiv.org/pdf/2212.08363
https://github.com/nielsschluesener/Fast-Learning-Hand-Gesture-Recognition
GitHub - nielsschluesener/Fast-Learning-Hand-Gesture-Recognition: Few Shot Learning Models for Hand Gesture Recognition
Few Shot Learning Models for Hand Gesture Recognition - nielsschluesener/Fast-Learning-Hand-Gesture-Recognition
github.com
Introduction
동적 손동작 인식 (Dynamic Hand Gesture Recognition, DHGR)은 로봇공학, 의료, 게임, 수화 번역 등 다양한 연구 분야에서 활용된다. 하지만 기존 연구는 표준 머신러닝(SML) 방식을 사용하여 고정된 Gesture Dataset 으로만 모델을 학습시키기 때문에 새로운 제스처를 추가하거나 변경할 때마다 많은 양의 데이터와 재학습이 필요하다는 문제가 있다. 이러한 한계를 극복하기 위해서 본 연구에서는 Few-Shot Learning 모델을 도입해 적은 수의 제스처 예시만으로도 빠르게 학습시킬 수 있는 방법을 제안한다. 또한 많은 모델들이 RGB-D 데이터로 학습이 되어있지만 접근성을 용이하게 하기 위해 RGB 비디오 데이터를 학습에 활용한다.
Related Work
Google Mediapipe를 사용해서 RGB 이미지 데이터를 통해 정밀한 손의 골격 데이터를 추출할 수 있게 되었다.

Few-Shot Learning: ‘N-Way K-Shot’으로 정의되며, N은 분류할 클래스 수, K는 각 클래스당 필요한 새로운 샘플 수. FSL 모델은 대규모 데이터셋으로 메타 학습(meta-training)을 수행하며, 소수의 샘플만으로도 새로운 작업에 빠르게 적응할 수 있다.
이 논문에서는 FSL 알고리즘 중에서 Relation Network(RN)을 사용하는데, 이는 새로운 것을 학습할 때 이미 알고 있는 몇 가지 예시와 새로운 대상을 직접 비교하여 그것이 무엇인지 판단하는 방식이다. 이미지 분류를 위해 개발되었지만 시퀀스 데이터 처리에도 좋은 성능을 보여 차용했다고 한다. 그러면 Relation Network의 일반적인 구조가 어떻게 되는지 살펴보겠다.
- 임베딩 모듈 (Embedding Module)
- 역할: 입력 데이터를 모델이 비교하기 좋은 형태로 변환하는 역할을 한다.
- 서포트 세트 (Support Set): Few-Shot 학습에서 "이것이 A야", "이것은 B야"라고 알려주는 몇 개의 예시 데이터들이다. 이 데이터들은 임베딩 모듈을 통과하여 각 클래스별 특징 맵(feature maps)으로 변환된다.
- 쿼리 세트 (Query Set): 모델이 '이것이 무엇일까?'라고 예측해야 하는 대상 데이터입니다. 이 데이터 역시 임베딩 모듈을 통과하여 특징 맵으로 변환됩니다.
- K-Shot 이상일 경우: 만약 각 클래스당 1개 이상의 예시(1-Shot 이상인 경우)가 있다면, support set에서 나온 특징 맵들을 합치거나 요약하여 하나의 대표적인 특징 맵을 만든다.
- 관계 모듈 (Relation Module)
- 역할: 임베딩 모듈에서 나온 특징 맵들을 비교하여, 쿼리 세트의 데이터가 지원 세트의 각 예시와 얼마나 '관계'가 있는지를 계산한다. 이것은 두 물건의 특징을 비교하여 얼마나 닮았는지 점수를 매기는 것과 같다.
- 구조: 임베딩 모듈에서 생성된 지원 세트와 쿼리 세트의 특징 맵들이 결합된다. 이 결합된 특징 맵들이 Relation Module로 들어가서, 각 쿼리 샘플과 지원 세트 샘플 간의 관계 점수(relation score)를 계산한다. 이 점수는 일반적으로 0에서 1 사이의 값으로 나오며, 1에 가까울수록 두 샘플이 유사하다는 뜻이다. 관계 모듈은 보통 Feed Forward 신경망과 같은 구조로 이루어져 있으며, ReLU와 같은 활성화 함수를 사용한다. 최종적으로 시그모이드 함수를 사용하여 0과 1 사이의 관계 점수를 출력한다.
이 논문의 차별점은 RGB 이미지 데이터 사용 + FSL 적용했다는 것이다. (2022년 12월 발표된 이 논문 기준으로 이전 연구들은 RGB-D 데이터에 의존하거나 FSL을 적용하지 않음)
Methodology
총 6개의 FSL 모델을 훈련하고 평가한다. (K=1, 2, 5 / N=5, 10) FSL 모델과 함께 SML 모델도 학습시켜 SML 모델이 FSL 모델의 accuracy를 넘어서기 위해 얼마나 많은 훈련 샘플이 필요한지 비교한다.
훈련 및 평가에는 Jester Dataset 사용한다. 하지만 이 데이터셋은 27가지의 제스처 클래스만 포함하고 있어 다양한 클래스로 메타 학습을 시킨다는 목적과 부합하지 않았다. 따라서 기존 클래스들을 조합하여 더 많고 복잡한 제스처 클래스들을 생성했다. 결과적으로 676개의 서로 다른 클래스(각 클래스는 기존의 hand gesture 두 가지를 조합), 169000개의 샘플을 가진 데이터셋 생성해냈다.


또한 원본 비디오 시퀀스를 Mediapipe Hands 라이브러리를 사용해 3차원의(x, y, z) 21개 골격 포인트 시퀀스로 변환해 모델의 복잡성을 크게 줄일 수 있었다.


임베딩 모듈(Embedding Module): query set, support set 샘플들을 입력 받아 각각 feature map을 계산한다. 만약 K>1일 경우(즉, 클래스당 여러 개의 샘플이 제공될 경우) support set의 feature map들을 요약한다.
관계 모듈(Relation Module): 임베딩 모듈에서 생성된 feature map드릉ㄹ 모두 연결한 후, 결합된 feature map들을 입력받는다. Support set의 각 인스턴스와 query set 간의 유사성을 나타내는 관계 점수(relation score)를 계한다. 관계 점수는 0과 1 사이의 스칼라 값이다.
본 연구에서의 RN의 구조에 약간의 변형을 주어 사용했다. 일반적인 RN에서는 backbone으로 CNN을 사용하지만 이 모델에서는 데이터의 순차적 특성을 잘 처리하기 위해 LSTM셀을 활용한다. Relation Module에서는 LSTM과 함께 Feed-Forward Network, ReLU 활성화 함수를 사용한다.
Result and Discussion
학습 데이터에 포함되지 않은 57개의 클래스로 구성된 데이터셋에 1000번의 테스트를 수행했다. 5가지 제스처를 분류하는 5-Way Task에서는 77.32%에서 88.84% 사이의 평균 정확도를 달성, 10가지 제스처를 분류하는 10-Way Task에서는 70.37%에서 81.28% 사이의 평균 정확도를 달성했다.
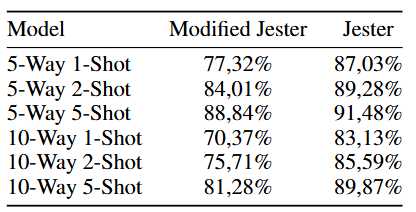
FSL 모델과 SML 모델을 비교한 결과는 다음과 같다.
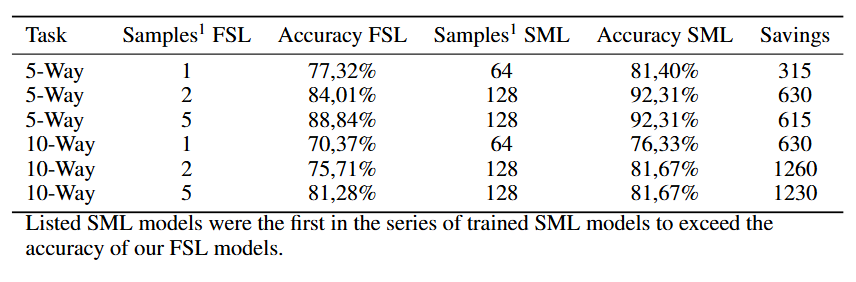
5-Way Learning의 경우 최대 630개의 sample을 절약했고, 10-Way Learning의 경우 최대 1230개의 샘플을 절약했다. 이는 FSL모델이 SML 모델에 비해 시간과 비용 측면에서 상당한 이점이 있음을 보여준다.
'컴퓨터 비전' 카테고리의 다른 글
| YOLO v1(You Only Look Once) 모델의 구조와 특징 (1) | 2026.02.18 |
|---|---|
| OHEM (Training Region-based Object Detectors with Online Hard Example Mining) (0) | 2026.02.15 |
| Fast R-CNN 과 Faster R-CNN (0) | 2026.02.12 |
| R-CNN (Regions with CNN features) (0) | 2026.02.10 |
| ResNet의 구조 (0) | 2026.01.30 |