R-CNN은 Object Detection Task 에서 CNN을 도입해 뛰어난 성능의 발전을 보여줬지만, 한계점이 명확했다.
- 이미지 하나당 2000개의 Region Proposal을 받고 각 영역에 대해서 CNN에 개별적으로 입력해 CNN 연산량이 너무 많았다.
- 학습 단계에서 ImageNet으로 CNN Pre-training, Detection 데이터로 CNN Fine-tuning, 클래스별 SVM학습, Bounding Box Regressor 학습 등을 모두 따로 진행해야 했다.
이 때문에 메모리 문제, 지나치게 많은 연산량과 오랜 연산시간 문제등이 있었다. Fast R-CNN과 Faster R-CNN은 R-CNN의 한계점을 보완해 연산량을 줄이는 동시에 Precision 역시 향상시켰다.
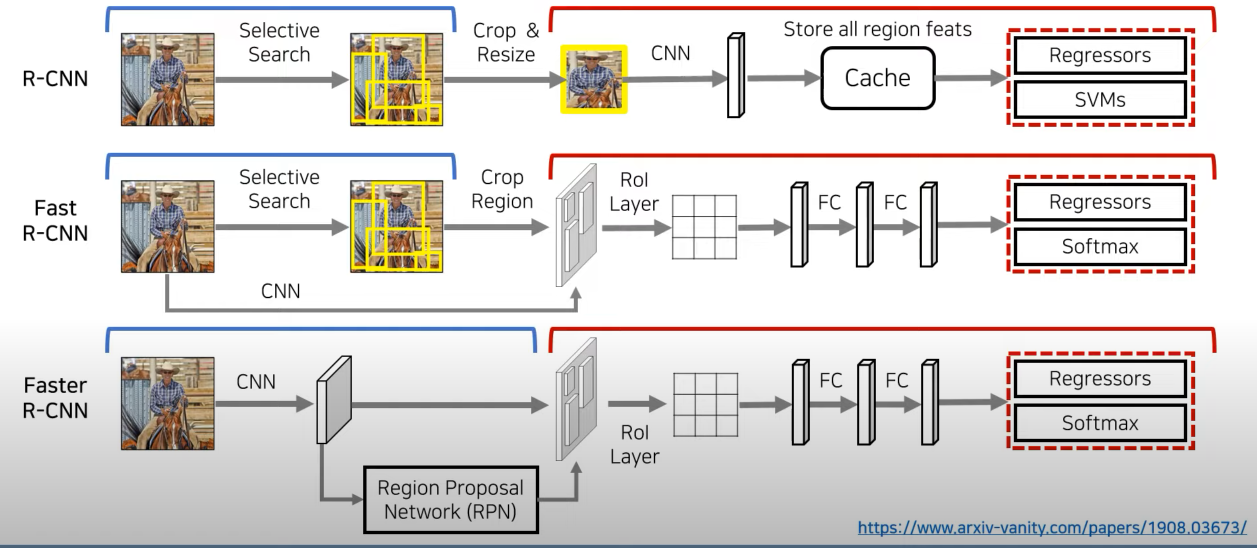
- Fast R-CNN
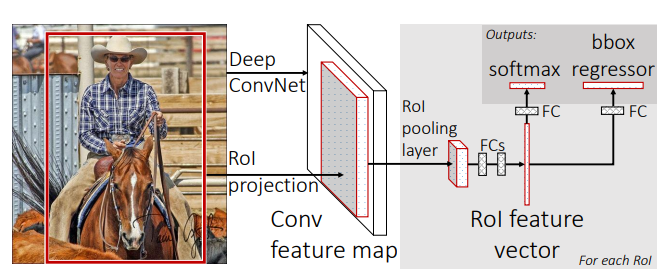
R-CNN과 마찬가지로 객체가 존재할만한 후보 영역을 추출하기 위해(Region Proposal) Selective Search 알고리즘을 사용한다. 하지만 R-CNN에서 모든 후보 영역들을 따로 CNN에 입력으로 넣어 Feature map을 생성한 것과 달리 R-CNN은 원본 이미지를 한번만 CNN에 입력으로 넣는다. 이렇게 하면 이미지의 전체 영역에 대한 공통 Feature map 하나를 얻을 수 있다.
이후 처음에 얻은 Region Proposal을 Feature Map 위에 투영시켜 "객체가 존재할 후보 영역에 대응하는 Feature 영역"을 얻는다.
이렇게 얻은 Feature Map 영역은 Region Proposal의 크기를 따라가기 때문에 각기 다른 크기를 가지고 있고, FC 레이어로 넘기기 전에 같은 크기로 조정해야 한다. 이를 위해 RoI Pooling(Region of Interest Pooling)을 사용한다.
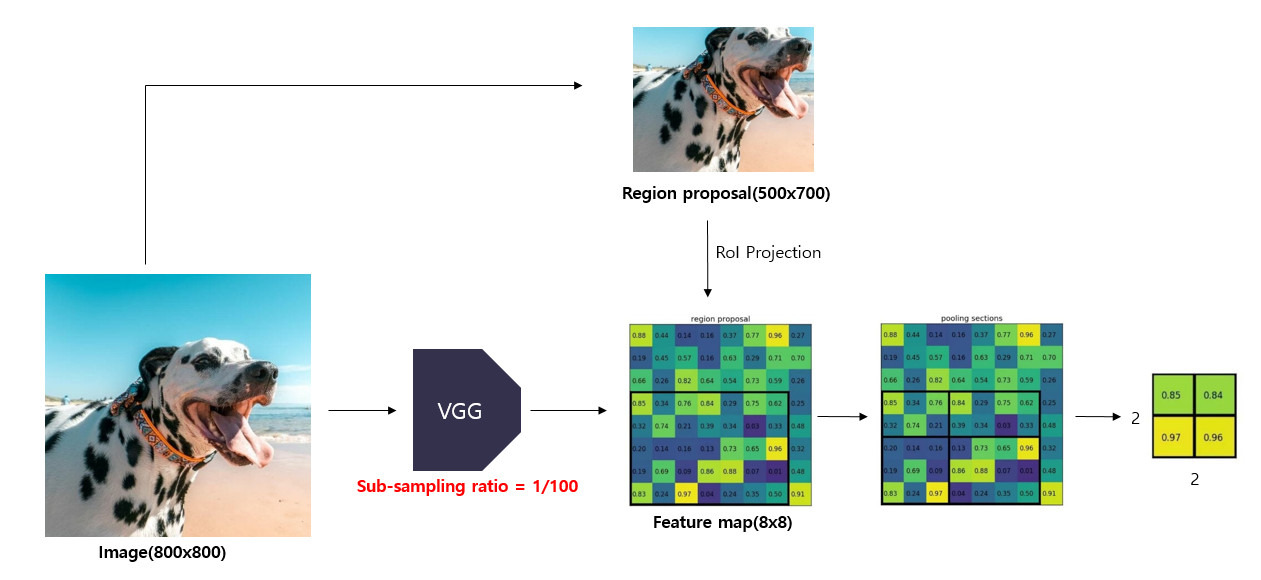
Region of Interest를 Outpoot 크기에 맞게 bin으로 쪼개고, 각 영역에서 가장 큰 값을 골라 Pooling 하는 것이다. 이렇게 Region Proposal 별로 고정된 크기의 Feature을 생성한다.
FC 레이어를 거친 후에는 Multi-task 으로 하나의 feature 에서 어떤 클래스에 해당할지 확률과 Bounding box 를 얼마나 이동시켜야 할지 위치 보정값을 동시에 예측한다. Classification의 경우 Softmax 를 사용해서 각 클래스에 해당할 확률을(background에 해당할 확률 포함) 한번에 계산한다. Bounding box regressor은 중심 x, y 좌표 이동량과 너비, 높이 조정 비율을 예측한다.
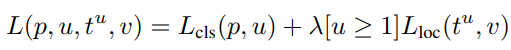
학습과정에서도 두 예측에 대한 Loss를 동시에 계산해 가중치를 업데이트한다. (R-CNN이 End-to-End 학습이 불가했던 점을 극복함)
- Faster R-CNN
Fast R-CNN에도 한계는 여전히 존재했다. Region Proposal을 Selective Search 알고리즘을 그대로 사용했는데, 이는 CPU에서 실행되는 연산이기 때문에 시간이 오래 걸렸다. Faster R-CNN 에서는 객체 후보 영역 추출도 CNN이 직접 예측하도록 바꿔 완전한 end-to-end CNN 구조를 구축한다.
이미지가 입력으로 주어지면 backbone CNN을 통해 원본 이미지에 대한 Feature Map을 생성한다. 논문에서 사용한 backbone CNN 아키텍쳐는 ZF, VGG-16 이다.
이제 생성된 Feature Map 위에서 객체 후보 영역을 찾는다. Faster R-CNN에서는 기존의 Selective Search 대신, CNN 기반의 객체 후보 영역 생성 모듈인 RPN(Region Proposal Network)을 사용한다. RPN의 목적은
feature map 위에서 물체가 있을 가능성이 높은 후보 영역(region proposal)을 빠르게 생성하는 것
이다!
- 우선 feature map 위에서 sliding window 역할을 해줄 3x3 convolution 을 진행한다. 크기가 변하지 않도록 stride=1, padding=1 을 사용한다.
- 두개의 convolution branch 를 사용해 각 anchor box에 물체가 존재할 확률 (classification branch), anchor box를 얼마나 변형시야 하는지 (regression branch) 계산한다. 여기서 anchor box는 region proposal 의 후보 영역들이라 생각하면 되는데, 각 feature map 의 위치마다 9개의 각기 다른 크기와 비율을 가진 anchor box 들이 있다. Classification branch 의 경우 각 anchor 마다 [background score, object score] 두개의 값이 출력되므로 9x2=18개의 채널이 필요하다. Regression branch는 9x4=36 채널이 필요하다.
- 위에서의 1x1 convolution 계산 결과를 토대로 물체일 확률이 낮은 anchor box 들을 제거하고 regression branch 의 값들을 통해 박스의 위치와 크기를 조정, Non-Maximum Suppresion 을 통해 겹치는 박스 중 점수가 높은 박스만 남기고 제거한다.

이후의 과정은 Fast R-CNN 과 동일하게 RoI Pooling, FC 레이어를 거쳐 Object Detection 이 이루어진다.
'컴퓨터 비전' 카테고리의 다른 글
| YOLO v1(You Only Look Once) 모델의 구조와 특징 (1) | 2026.02.18 |
|---|---|
| OHEM (Training Region-based Object Detectors with Online Hard Example Mining) (0) | 2026.02.15 |
| R-CNN (Regions with CNN features) (0) | 2026.02.10 |
| ResNet의 구조 (0) | 2026.01.30 |
| VGG-Net 구조와 구현 (0) | 2026.01.29 |