컴퓨터비전의 대표적 테스크인 Object Detection(객체 탐지)는 이미지 내에 존재하는 객체는 무엇이 있는지, 그 객체의 위치는 어디인지 찾아내는 것이다. 이태까지 살펴본 AlexNet, Vgg-Net, ResNet 등은 모두 이미지가 내에 무엇이 있는지 분류하는 Classification 을 위한 모델이었다. Object Detection은 여기에 추가적으로 객체의 위치까지 특정할 수 있어야 하니 더 복잡하다고 볼 수 있다.

기존의 객체 담지 모델들 중 가장 좋은 성능을 보인 것은 SIFT, HOG 같은 고전적인 알고리즘들 기반 + SVM 이었다고 한다. 2014년에 CNN을 도입한 객체 탐지 모델이 나와 훨씬 뛰어난 성능을 보여주는데, 이것이 바로 R-CNN 이다. R-CNN의 구조를 살펴보자.
https://arxiv.org/abs/1311.2524
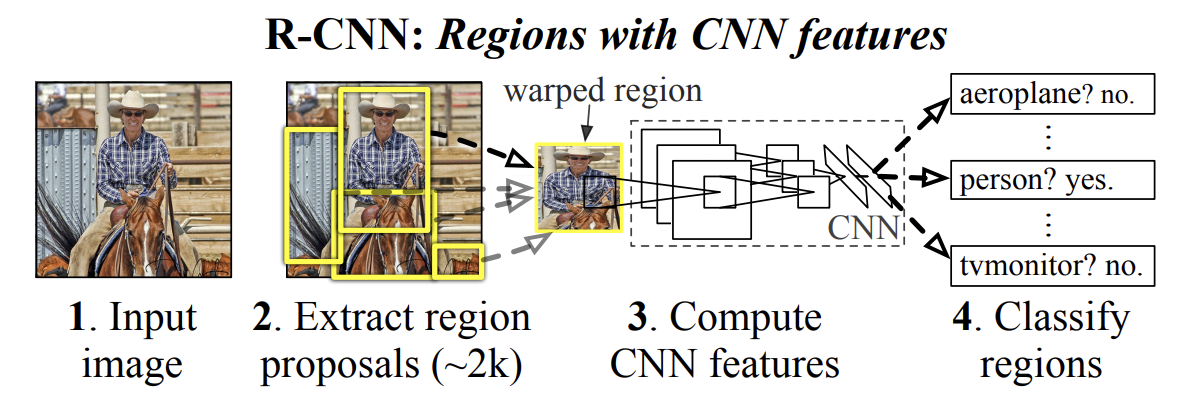
- Region Proposals
우선 이미지 내에서 객체가 존재할만한 위치를 찾아야 한다. 여기에 Selective Search 라는 알고리즘이 사용된다. Selective Search 의 과정은 간단히 다음과 같다: 이미지를 Superpixel 이라는 작은 단위들로 나눈다. 이후 맞닿아있는 영역들을 비교하면서 유사도가 높은 영역들을 하나로 합친다. 이렇게 "그럴듯한 픽셀 덩어리"가 생기면 이를 감싸는 박스를 Proposal 로 사용하는 것이다. 이렇게 객체가 있을 만한 박스 후보들을 2000개 가량 추출한다.

이러한 노란 박스들이 실제로는 2000개 추출된다고 생각하면 된다.
- Feature Extraction
각 후보 박스에서 이미지의 "특징 벡터"를 추출하는 단계이다. 첫번째 단계에서 추출된 모든 후보 박스들을 CNN 모델에 입력으로 넣어 4096차원 Feature Vector 을 만들어낸다. 입력으로 넣을 사이즈는 227x227으로 고정되어 있기 때문에 Proposal Box 의 크기가 이와 다를 경우 Image Warp 를 통해 크기를 조정한다. CNN은 5개의 Convolutional Layer, 2개의 Fully-Connected Layer으로 구성되어 있다. 2000개의 후보 영역들에 대해서 CNN을 모두 돌려야 하기 때문에 이 단계에서 시간이 많이 소요된다.
여기서 CNN 레이어들은 ILSVRC2012 classification 데이터셋으로 Pre-train 되었다. 물론 R-CNN은 Classification이 아니라 Object Detection 이라는 살짝 다른 목표를 가지고 있지만, 이렇게 대규모 이미지 데이터셋으로 Pre-train함으로 인해서 CNN 레이어들이 일반적인 시작적 특징을 추출하는 능력을 지니게 초기화된다. 이후 CNN 레이어 가중치들을 Object Detection에 적합하게 업데이트하기 위헤 Domain-specific fine tuning을 진행한다. 이미지넷의 마지막 1000-class classification layer 대신 Fine tuning에 사용될 데이터셋의 클래스+1(배경) 분류 레이어를 만들고 SGD로 가중치를 업데이트한다.
- Classification
위에서 만들어낸 Feature Vector을 Pre-train 되어있는 클래스별 선형 SVM(Class specific detection linear SVM)에 입력으로 주어 각 클래스에 해당하는 객체가 존재할 확률값을 계산한다. (모든 객체 종류에 대한 확률값을 한번에 계산하는 AlexNet 등의 Softmax 활용과는 다른 방식이다) ILSVRC2013의 경우 클래스가 200개 이므로 선형 SVM은 200개가 존재하고, 각 200개 클래스 별 확률을 따로 계산하게 된다.

위와 같이 각 Proposal Box에 대해서 특정 클래스에 해당할 확률이 계산된다. 햄버거 영역에 대해서 햄버거일 확률이 0.78이 나온걸 보니 잘 찾아냈다.
R-CNN에서 Softmax 가 아닌 SVM을 사용한 이유는 대부분의 Proposal Box는 객체 정보가 아닌 배경 정보를 담고 있고, Softmax를 사용할 경우 총합 1의 확률 분포를 강제하기 때문에 원래는 배경으로 분류되어야 할 부분이 객체로 오분류될 위험성이 비교적 크기 때문이다.
- Bounding Box Regression, Non-Maximum Suppression
기존의 Box 는 정답에 비해 위치나 크기가 어긋날 수 있어 Regression을 통해 박스의 위치/크기를 정답에 맞게 미세 보정한다.
Non-Maximum Suppression은 겹치는 중복 박스를 제거하는 것이다. 같은 물체에 대해서 거의 똑같은 박스들이 여러개 남아있을 확률이 높은데, 우리는 여러개의 중복된 박스들이 필요하지 않기 때문에 이들을 제거해준다. 방식은 클래스별로 Score이 높은 순서대로 박스들을 정렬하고, 가장 높은 박스와 겹치는 영역 비율 (IOU, Intersection-over-union) 큰 박스들을 제거하는 작업을 반복한다.
'컴퓨터 비전' 카테고리의 다른 글
| OHEM (Training Region-based Object Detectors with Online Hard Example Mining) (0) | 2026.02.15 |
|---|---|
| Fast R-CNN 과 Faster R-CNN (0) | 2026.02.12 |
| ResNet의 구조 (0) | 2026.01.30 |
| VGG-Net 구조와 구현 (0) | 2026.01.29 |
| AlexNet 구현, CIFAR-10 이미지 분류하기 (0) | 2026.01.14 |