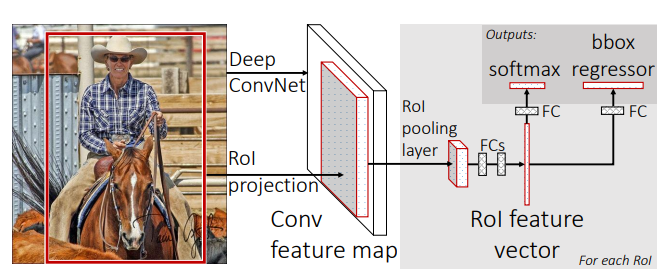
Object Detection을 위한 모델을 학습시킬 때 모델에게 Positive sample(객체가 있는 영역과 클래스를 올바르게 분류한 bounding box), Negative sample(그렇지 못한 bounding box)를 제공해야 한다. 문제는 대부분의 이미지에서 객체를 포함하고 있는 영역은 일부이고 대부분은 탐지의 대상이 아닌 '배경'으로 이루어져 있다. 따라서 객체를 올바르게 감싸고 있는 Positive sample에 비해 Negative sample의 숫자가 훨씬 많다. 뿐만 아니라 대부분의 Negative Sample들은 학습에 크게 도움이 되지 않고, 실제로 모델의 성능을 좌우하는 Sample들(물체의 일부만 포함한 box, 서로 겹치는 물체, 배경과 유사한 물체)의 비중은 적다...