오늘은 Object Detection 분야에서 중요한 전환점을 만든 1-stage detector의 시초격 모델인 YOLO v1을 살펴보겠다. 기존의 R-CNN, Fast R-CNN, Faster R-CNN과 같은 모델들은 모두 2-stage detector 구조를 따랐다. 이들 모델은 먼저 객체가 존재할 가능성이 있는 영역을 제안한 뒤, 해당 영역에 대해 분류와 박스 회귀를 수행하는 두 단계의 과정을 거친다. Faster R-CNN은 RPN을 도입하여 이 과정을 CNN 기반으로 통합했지만, 여전히 제안 영역 생성과 최종 분류·회귀 단계가 구조적으로 분리되어 있었다.
반면 YOLO 모델은 객체가 존재할 영역 탐지와 분류를 하나의 단계로 통합한 1-stage detector이다. 입력 이미지를 한 번의 CNN 통과로 처리하면서 네트워크가 곧바로 객체의 위치와 클래스를 동시에 예측한다. 따라서 객체가 있을 것으로 예상되는 각 영역마다 별도의 CNN 연산을 반복할 필요가 없다. 이러한 단순화된 파이프라인 덕분에 기존 Object Detection SOTA 모델들에 비해 정확도는 다소 낮았지만, 예측 속도 측면에서는 획기적인 발전을 이루었다. 실제로 당시의 하드웨어 환경에서도 초당 약 45장의 이미지를 처리하며, 최초로 실시간 객체 탐지의 가능성을 제시한 모델로 평가된다.

이제 YOLO가 어떻게 객체 영역 탐지와 분류를 동시에 해내는지 구조를 살펴보겠다.
- 입력 이미지를 S x S grid로 나눈다. (논문 기준 S=7) 각 grid는 자신의 영역 내부에 객체의 중심이 있다면 책임지고 그 객체의 bounding box와 classification을 예측한다.

이미지를 7x7 격자로 나눈 예시
위 그림을 예시로 보면, 강아지 객체의 중심은 하늘색 점이고 해당 점이 위치한 5행 2열의 격자가 책 임을 지고 강아지에 대한 Classification을 해내야 하는 것이다. Box 예측값의 중심은 해당 grid 안에서 존재해야 한다. - 각 Grid Cell 에서는 B개의 bounding box를 예측한다. (논문 기준 B=2) 각 bounding box는 중심 좌표 (x, y), 너비와 높이 (w, h), 그리고 confidence 값을 가지며, grid cell 단위로 C개의 클래스 확률도 함께 예측된다.
- confidence score는 "해당 박스가 객체를 얼마나 잘 포함하고 있을 것으로 예상하는가"를 나타내는 값으로 볼 수 있다. Training 단계에서 이 값은 다음과 같이 정의된다.
- confidence=P(object)×IoU(truth,pred)
- P(object): 객체의 중심이 해당 grid cell 안에 있으면 1, 아니면 0. 셀 내부의 B개 bounding box 중에서는, ground truth box와의 IOU가 더 큰 박스가 P(object)=1 을 가져가며 나머지는 0이 된다. 여기서 객체의 중심은 ground truth bounding box의 중심을 의미한다.
- IoU(truth, pred): Ground truth box와 예측한 bounding box 사이의 IoU 값.
- 각 bounding box 마다 최종 점수를 계산한다: score = class_prob x confidence. 이 점수가 높은 박스만 남기고 나머지는 객체를 포함하고 있을 확률이 낮다고 판단해 제거한다. 동일한 객체를 가리키는 박스가 여러개 중복으로 추론되었을 가능성이 있기 떄문에 NMS(Non-Maximum Suppression)을 사용해 하나만 남긴다.
- 결과적으로 각 grid cell 마다 객체가 존재할 가능성이 있는 bounding box 들이 B개, 각 bounding box 마다 객체가 어떤 클래스에 해당될지, 그리고 그 박스가 실제 객체를 얼마나 잘 포함하고 있을지를(confidence) 동시에 예측하는 구조를 가진다.
- YOLO의 전체 구조
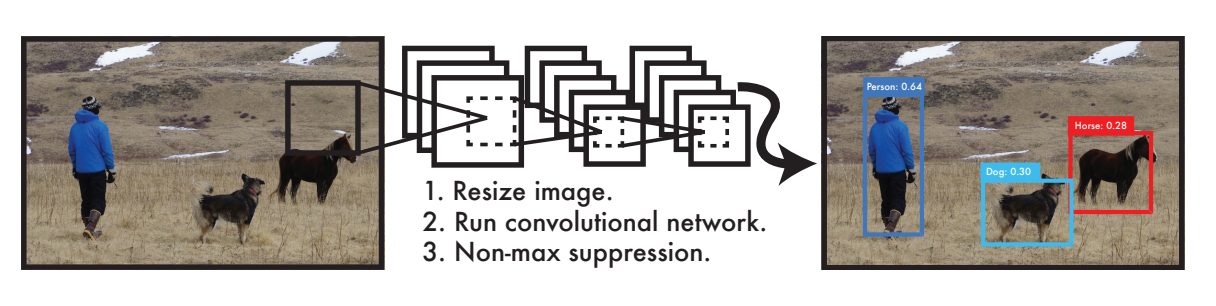
YOLO의 전체 구조는 단순하다. 이미지를 448 x 448 으로 Resize 하고 하나의 CNN 네트워크에 입력으로 넣어 결과값들을 얻는다. 마지막으로 NMS를 통해 객체로 최종 판단할 bounding box들을 남긴다.

위 CNN 아키텍쳐는 DarkNet으로, YOLO의 마지막에 최종 예측값 크기인 7 x 7 x 30 출력 레이어를 만들기 위해서 (일반적으로는 S x S x (Bx5+C) ) 독자적으로 구축했다고 한다. 입력 이미지를 448 x448 크기로 받는데, 당시에 객체 탐지를 하기 위해서는 224 x 224 이미지보다 high resolution으로 많은 정보가 필요하다고 생각했기 때문에 입력 크기를 늘렸다고 한다.
이전의 모델들과 다르게 특정 영역에 대한 Convolution 계산을 따로 진행하지 않고 이미지 전체에서 시작된 CNN 네트워크가 쭉 이어진다. 때문에 이미지 전체의 맥락을 파악하는 성능이 뛰어나 배경에 의한 객체 오탐지 혼동이 줄었다고 한다.
- Loss Function
Loss Function은 크게 3가지 부분으로 구성되어 있는데, bounding box를 얼마나 잘 예측했는지 나타내는 Localization Loss, bounding box의 객체 존재 여부 판단에 대한 오차인 Confidence Loss, 그리고 객체 분류에 대한 오차인 Classification Loss 세가지의 합으로 이루어진다. 하나씩 살펴보겠다.
*참고로 Loss Function은 Grid Cell 내부에 객체의 중심이 존재할 때만 계산되고, 이외의 경우는 0이다.
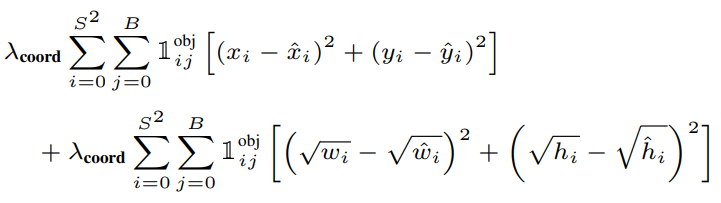
객체 예측에 책임이 있는 bounding box에 대해서 ground truth box와의 좌표 차이, 크기 차이가 오차로 계산된다. P(object)=0, 즉 객체 예측에 책임이 없는 bounding box는 오차에 기여하지 않는다.
위 식에서 λ = 5이다. 다른 파트에 비해서 Localization Loss 계수를 더 높게 두는 것이 학습이 잘 된다고 한다.

객체 예측에 책임이 있는 bounding box일 경우와(윗줄) 객체 예측에 책임이 없는 bounding box일 경우를(아랫줄) 나누어 계산한다. 위 식에서 λ = 0.5 인데, 객체가 없는 bounding box 에서 발생한 오차의 비중을 상대적으로 줄이는 것이다. 이는 학습 시에 객체 예측에 책임이 없는 bounding box 수가 훨씬 많기 때문에 동일 비중으로 합하면 모델 전체가 confidence score이 0에 가까워지는 방향으로 학습될 수 있기 때문이다.

Classification Loss 파트에서는 grid cell 별로 classification 오차를 계산한다. 객체가 존재하지 않는 경우 오차에 기여하지 않는다.
마지막으로 논문을 읽으면서 햇갈렸던 내용들을 Q&A 방식으로 정리해보겠다.
Q: Non-Maximum Suppression 을 통해서 같은 객체를 가리키는 bounding box들이 여러개 나오면 중복 탈락을 시키는데, 이때 같은 grid cell 내부의 bounding box들에 대해서만 NMS를 진행하는가? 아니면 다른 grid cell 출신의 box 끼리도 탈락을 시키는가?
A: 다른 grid cell에서 나온 box 끼리도 NMS를 진행한다. NMS는 전체 이미지 단위에서 동작하는 것이다.
Q: Training Data에서 같은 grid cell 안에 객체의 중심이 2개 이상 존재하는 것이 가능한가? 학습 단계에서 하나의 grid cell은 하나의 object detect 을 담당하고. 해당 grid 에서 담당하는 ground truth object 과의 IoU가 가장 큰 bounding box 만 살아남고 나머지는 P(object)=0 으로 죽는다. 그런데 만약에 원본 이미지에서 하나의 grid cell 안에 "정답 객체" 로 학습할만한 것이 2개 이상 존재한다면? 애초에 이런 데이터는 포함되어있지 않은 것일까?
A: 실제로 학습시 grid cell 안에 중심이 위치한 하나의 객체만 사용되고 나머지는 무시된다. 때문에 작은 객체 탐지, 밀집 객체 탐지에 약해지는데, 작은 객체는 한 cell 에 여러개가 들어가기 쉽기 때문이다. 대표적인 YOLO v1의 약점이라고 한다.
Q: 하나의 grid cell 안에서 객체와의 IoU가 가장 높은 박스만 P=1로 학습시키고 나머지는 P=0으로 "객체가 존재하지 않음" 으로 신경망을 학습시킨다면 성능이 저하될 수 있지 않을까? 예를 들어, 애초에 Prediction box 2개가 Ground Truth 와의 IoU 값이 거의 차이가 나지 않는다고 생각해보자. (0.71, 0.69) 따라서 두 box 모두 객체의 영역을 잘 예측했는가라는 측면에서 크게 성능 차이가 없는데 하나는 1, 하나는 0이 된 상태로 train 시켜도 괜찮은건가?
A: Box 2개를 다 같은 객체를 인식하도록 학습하면 역할 분담이 안 생기고 중복 탐지가 증가한다. 또한 가중치 학습을 위해서 오차를 계산할 때 Confidence Loss 파트에 의한 오차 증가는 있지만 0.5를 곱해주기 때문에 비중이 작다. 그리고 역할이 분담되면서 자연스럽게 다른 형태, 크기의 객체 탐지에 특화된다.
'컴퓨터 비전' 카테고리의 다른 글
| Fast Learning of Dynamic Hand Gesture Recognition with Few-Shot Learning Models 논문 리뷰: 적은 수의 영상으로 제스처 학습시키기 (2) | 2026.02.28 |
|---|---|
| OHEM (Training Region-based Object Detectors with Online Hard Example Mining) (0) | 2026.02.15 |
| Fast R-CNN 과 Faster R-CNN (0) | 2026.02.12 |
| R-CNN (Regions with CNN features) (0) | 2026.02.10 |
| ResNet의 구조 (0) | 2026.01.30 |