openCV 라이브러리를 활용해 문서 스캔을 해주는 프로그램을 만들어 보기로 했다. 처음에 구상한 구조는 다음과 같았다.
웹캠을 사용해 문서가 포함된 사진을 촬영한다
↓
Grayscaling 적용
↓
이미지에 Blur / Dilate 를 적용한다
↓
Corner detection 을 통해 이미지 내 문서의 네 모서리 좌표를 구한다
↓
구한 좌표를 토대로 Perspective Transform 을 적용해 문서로 꽉 채운 이미지를 만든다
우선 촬영한 이미지에 Blurring, Dilation 적용 없이 Corner Detection을 해보았다. Corner Detection에는 openCV의 goodFeaturesToTrack() 함수를 사용했다.
corners = cv2.goodFeaturesToTrack(img_gray, 4, 0.5, 500)
corners = np.int32(corners)
for corner in corners:
x, y = corner.ravel()
cv2.circle(img, (x, y), 20, (0, 0, 255), -1)

빨간 점들이 detect 한 corner 들이다. 글자들이 코너로 검출된 모습이다. 이것이 바로 이미지에 Blurring 과 Dilation 을 적용해야겠다고 생각했던 이유다. Dilation 을 적용하면 하얀 배경 안의 검은색 noise(글자) 부분을 하얀색으로 채울 수 있다.
이번엔 계획한대로 Gaussian Blurring과 Dilation을 적용한 후 Corner Detection을 다시 시도해보자.
Gaussian = cv2.GaussianBlur(img_gray, (31, 31), 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
img_dilated = cv2.dilate(Gaussian, kernel, iterations=20)
corners = cv2.goodFeaturesToTrack(img_dilated, 4, 0.5, 500)
corners = np.int32(corners)
for corner in corners:
x, y = corner.ravel()
cv2.circle(img, (x, y), 20, (0, 0, 255), -1)

여전히 의도한대로 문서의 Corner 을 찾지 못한다. 이 방법에는 두가지 문제점이 있었다.
- Dilation에 의해서 문서의 끝 부분이 확장된다. Iteration 횟수가 늘어날수록 정도는 커진다.
- 작은 글자들은 효과적으로 없앴지만 여전히 그림이나 큰 글자들은 사라지지 않고 Corner Detection에 방해가 된다. 물론 kernel을 확장시키거나 iteration 횟수를 더욱 늘리면 해결될지도 모르지만 첫번째 문제가 더 커질 것이다.
문서 크기 변형 문제를 해결하기 위해 Closing (Dilation - Erosion) 후 Corner Detection 역시 시도해봤지만 글자가 계속해서 모서리로 판별되는 문제를 해결하기에 충분하지 않았다. 이에 방법을 바꿔서 객체의 경계를 찾아주는 findContours()를 활용해보기로 했다.
cv2.findContours()는 이진화된 이미지를 입력받아 이미지 내 객체들의 경계를 찾아준다.
_, thresh_binary = cv2.threshold(img_gray, 150, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh_binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, contours, -1, (0, 255, 0), 2)

책의 경계를 잘 찾아냈다! 여기서는 따로 Blurring 이나 Dilation 같은 전처리 과정을 거치지 않아도 괜찮다. 비록 문서 영역 내부의 글자와 그림이 사라지지 않지만 findContours()를 통해 찾아낸 객체 중 가장 큰 것을 문서로 판별해내면 되기 때문이다.Blurring 이나 Dilation를 사용해 전처리한 후 경계 탐색을 해본 결과 오히려책의 경계 중 일부가 손실되는 악영향이 있었다.
이제 가장 큰 객체를 찾고, 모서리의 좌표를 구해보겠다.
sortedContours = sorted(contours, key=cv2.contourArea, reverse=True)
cv2.drawContours(img, [sortedContours[0]], -1, (0, 255, 0), 3)
peri = cv2.arcLength(sortedContours[0], True)
approx = cv2.approxPolyDP(sortedContours[0], 0.02 * peri, True)
approx = np.squeeze(approx, axis=1)
print(f"꼭짓점의 수: {len(approx)}")
print(approx)
객체들을 contourArea 크기를 기준으로 내림차순으로 정렬해 가장 면적이 넓은 객체(여기서는 문서)를 구했다.
cv2.approxPolyDP()를 통해서 객체의 윤곽선을 다각형으로 근사한다. 꼭짓점들의 좌표가 리턴되는데, 이때 리턴된 꼭짓점의 수가 4가 아닌 경우 객체 검출 단계 혹은 다각형 근사 단계에서 오류가 발생한 것으로 판단할 수 있다.
# 순서대로 좌상단, 좌하단, 우상단, 우하단으로 정렬
corners = sorted(approx, key=lambda x: x[0]+x[1])
if corners[1][1] < corners[2][1]:
corners[1], corners[2] = corners[2], corners[1]
src = np.float32(corners)
dst = np.float32([[0, 0], [0, 1754], [1240, 0], [1240, 1754]])
M = cv2.getPerspectiveTransform(src, dst)
dst = cv2.warpPerspective(img_rgb, M, (1240, 1754))
이후 리턴된 꼭짓점들을 정렬하고 Perspective Transform 을 진행한다.
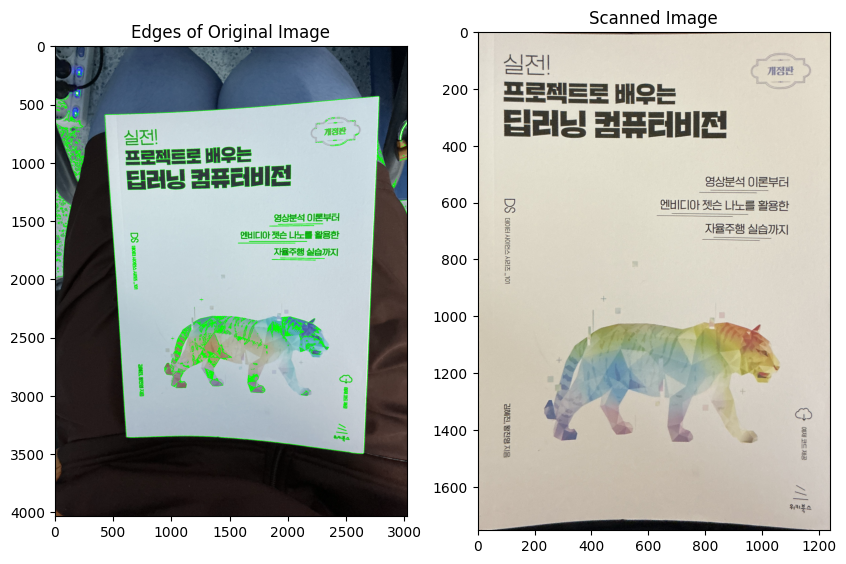
결과는 성공적이다! 다음에는 이 프로그램을 streamlit에 올리고 다른 사진들에도 시도해보겠다.
'컴퓨터 비전' 카테고리의 다른 글
| AlexNet의 구조와 구현 (0) | 2026.01.10 |
|---|---|
| 이미지에서의 Edge Detection (First Derivative, Laplacian, Canny Edge Detection) (0) | 2026.01.04 |
| openCV 활용한 문서 스캐너 프로그램 만들기(2) (0) | 2025.12.28 |
| PCA(주성분 분석)를 통해 이미지에서 특성 추출하기 - (2) (0) | 2025.11.14 |
| PCA(주성분 분석)를 통해 이미지에서 특성 추출하기 - (1) (0) | 2025.11.14 |