만약 영상 속에 있는 인물의 시점으로 영상을 재구성할 수 있다면 어떨까? 이 논문에서는 그 작업을 잘 수행해내는 모델을 제시한다. EgoX는 하나의 Exocentric 비디오만을 입력하여, 영상 속 인물의 눈으로 보는 듯한 현실적인 Egocentric 비디오를 생성하는 프레임워크이다.
https://arxiv.org/pdf/2512.08269
https://keh0t0.github.io/EgoX/
첨부한 이미지들의 출처는 모두 위 논문이다.

Introduction
이 주제는 Exocentric (3인칭) 비디오를 Egocentric (1인칭) 비디오로 변환하여 영상 속 인물에 몰입하는 듯한 경험을 가능하게 하지만, 모델은 보이는 영역을 재구성하고 보이지 않는 영역은 사실적으로 합성해내야 하기 때문에 매우 어려운 문제이다. 또한 외부 시점의 작은 부분만이 1인칭 시점에 포함되므로 사용되어야 할 시점 관련 정보와 억제되어야 할 정보를 구별하는 것이 중요하다.
기존에도 EgoX와 비슷한 시도를 한 모델들이 있었다. 기존의 camera contrl video generation 모델들은 주로 완만한 시점(viewpoint) 변화에 초점을 맞추어, Exocentric-to-Egocentric 비디오 생성과 같은 극단적인 카메라 포즈 변환을 처리하는 데 적용하기 어렵다. 또한, 이전 접근 방식들은 Egocentric 뷰를 처음부터 생성하는 것을 피하거나 추가 입력(예: 첫 Egocentric 프레임, 다중 Exocentric 뷰)을 요구하여 문제 설정을 단순화했다.
EgoX 모델은 3인칭 영상의 1인칭 변환이라는 과제를 효과적으로 달성하기 위해 다음과 같은 방식을 사용한다.
- 대규모 비디오 Diffusion Model의 사전 학습된 시공간적 지식(spatio-temporal knowledge)을 효과적으로 활용
- Exocentric 비디오와 Egocentric prior를 width-wise 및 channel-wise concatenation을 통해 통합하는 전략을 설계하여 견고한 기하학적 일관성(geometric consistency)과 고품질 생성을 달성한다. 이를 위해 경량의 LoRA-based adaptation을 활용한다.
- Geometry-Guided Self-Attention (GGA): 1인칭 view에 관련된 영역에 선택적으로 집중하고 관련 없는 영역을 억제하는 Geometry-Guided Self-Attention을 도입하여 Egocentric 합성의 일관성을 높인다.
이제 모델의 구조를 자세히 살펴보겠다.
Methods

1. Egocentric Point Cloud Rendering
각 프레임에 대해 단일 이미지 깊이 추정기(single-image depth estimator)를 사용하여 깊이 맵 Dm을 추정한다. Dm은 프레임 별로 독립적으로 추정되기 때문에 특정 시점의 디테일을 잘 포착하지만 프레임 별로 약간의 불일치가 발생할 수 있다.
또한 비디오 기반 시간적 깊이 추정기(temporal depth estimator)를 사용하여 비디오 기반 깊이 맵 Dv를 추정한다. Dv는 시간적으로 부드럽지만 독립적인 스케일 정보가 비교적 부족하다.
Dm, Dv 각각의 장점을 조합하기 위해, Dv를 Dm과 시간적으로 정렬한다. 이를 위해 모멘텀 기반 업데이트 전략을 사용하여 각 프레임에 대한 Affine Transformation 파라미터 α와 β를 최적화하고, 최종 정렬된 깊이 맵 Df를 계산한다. 이때 동적 객체는 마스킹되어 정적 배경 영역만 사용된다.

정렬된 깊이 맵 Df를 해당 카메라 내부 파라미터와 함께 사용하여 3D 포인트 클라우드로 변환한다. 그런 다음, 포인트 클라우드 렌더러를 사용하여 Exocentric RGB 비디오 X, 정렬된 깊이 맵 Df, egocentric 카메라 포즈 ϕ를 입력받아 내전 사전 비디오 P를 렌더링한다. 렌더링에는 PyTorch3D를 사용했다고 한다.

이 과정을 통해 얻어진 내전 사전 비디오 P는 후속 Video Diffusion 모델에 입력으로 사용되어, 극심한 시점 변화에도 불구하고 사실적이고 기하학적으로 일관된 Egocentric Video 생성을 돕는다.

2. Exo-to-Ego View Generation with Video Diffusion Models
Exocentric Video X, 위에서 렌더링한 Egocentric Prior Video P를 VAE에 입력으로 넣어 잠재 특징 x0, p0을 얻는다. (VAE는 데이터를 저차원의 latent space으로 압축했다가 원래 데이터로 복원하는 모델임. latent vector은 데이터의 핵심적 특징을 함축하고 있다.)
x0 : 입력된 exocentric video를 VAE encoder로 통과시켜 얻은 잠재 특징(latent features). 이는 원본 exocentric 비디오의 내용을 압축한 정보라고 볼 수 있다.
p0 : 렌더링된 egocentric prior video를 VAE encoder로 통과시켜 얻은 잠재 특징. 이는 목표하는 egocentric 시점에서의 장면 정보를 담고 있다.
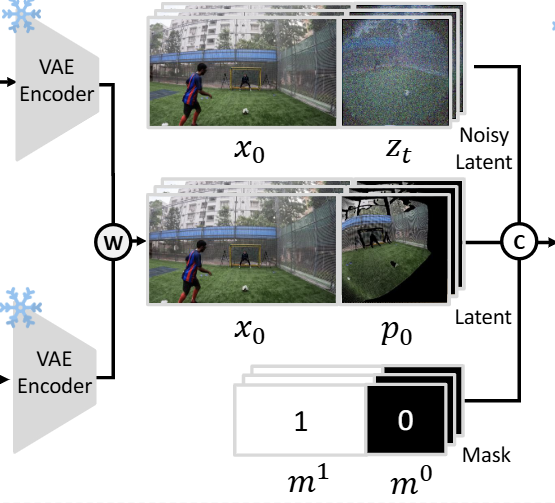
채널 차원을 따라 p0을 zt(목표 egocentric 시점의 노이즈가 낀 정보)와 연결하여, 생성 과정 동안 시점 정렬 및 시간적 일관성을 갖춘 가이던스를 제공하게 한다(egocentric 시점에서 보이는 영역에 대한 기하학적 단서 제공). p0는 목표 시점의 시각적 정보와 카메라 궤적에 대한 단서를 이미 가지고 있기 때문에, 이를 채널 방향으로 결합함으로써 모델은 목표 시점에 대한 정확한 안내를 받을 수 있다.
너비 차원을 따라 x0를 zt와 연결하여, 모델이 교차 시점 대응 관계 (3인칭 시점 영상과 1인칭 시점 영상 사이의 관계)를 추론하고 공간적 왜곡을 수행하도록 도움(provide broader scence context). Width-wise concatenation을 통해 두 정보를 나란히 놓음으로써 “3인칭 영상의 이 부분이 1인칭 영상의 저 부분에 해당하겠구나” 라는 cross-view correlation을 모델이 스스로 학습하게 한다. 마치 두 개의 독립적인 정보를 나란히 놓고 비교하듯이, 모델이 다른 시점 간의 관계를 암묵적으로 추론하고 필요한 부분을 추출하도록 유도하는 효과가 있는 것이다.
3. Geometry-Guided Self-Attention

Exocentric video condition 에는 1인칭 시점과 관련이 없는, 오히려 모델을 산만하게 할 수 있는 영역이 포함된다. 이를 해결하기 위해 3인칭 시점과 1인칭 시점 간의 공간적 대응 영역에 집중하기 위해서 Geometry-Guided Self-Attention (GGA)를 도입한다.
이 메커니즘은 셀프 어텐션(self-attention)에 3D 기하학적 정보를 통합하여, Exocentric 비디오의 내용 중 Egocentric 시점과 공간적으로 일치하는 영역에 더 집중하도록 한다.
앞서 얻은 3D point cloud를 활용해서 Egocentric 카메라 센터에서 각 Egocentric query와 Exocentric Key 토큰 까지의 3D 방향 벡터를 계산하고 두 방향 벡터 간의 Cosine Similarity를 계산한다. 기하학적으로 정렬된 영역은 더 높은 어텐션 가중치를 받아 모델이 해당 정보를 더 중요하게 활용하게 된다. 반대로 관련 없거나 잘못 정렬됐다고 판단된 영역은 억제되어 더 일관적이고 사실적인 영상 생성이 가능해진다.

GGA를 사용했을 때 모델이 중요한 영역에 더 집중하는 것을 확인할 수 있다.
Experiments

타 모델들에 비해 훨씬 사실적인 1인칭 비디오를 생성해낸 모습이다.
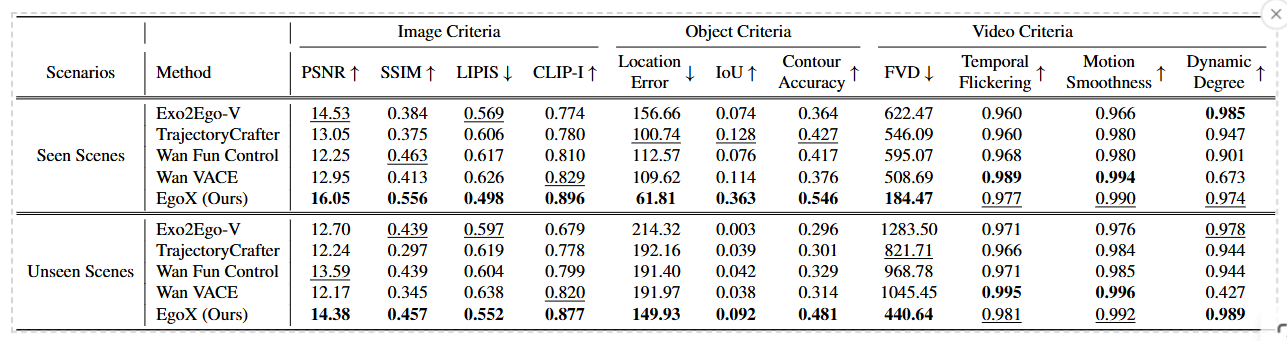
생성 결과의 Location Error, Iou, Contour Accuarcy 모두 기존 모델들에 비해 훨씬 우수한 성능을 보인다.