머신러닝을 하면서 SVM을 데이터 피처 증강에 사용해본 적은 있지만 그 원리에 대해 자세히 공부해본 적이 없었다. 그래서 이번에 따로 공부도 해볼겸 여기에 내용을 정리해보겠다!
SVM(Support Vector Machine)은 분류에 사용되는 지도학습 알고리즘으로, 데이터를 가장 잘 구분할 수 있는 결정 경계를 찾는 것이 알고리즘의 목표이다. 여기서 결정 경계를 초명면이라고도 부른다. n 차원의 데이터를 구분짓는 결정 경계(초명면)는 n-1 차원이 된다. (데이터가 2차원이면 직선, 3차원이면 평면, ....)
SVM은 결정 경계를 기준으로 마진(결정 경계와 가장 가까운 데이터 포인트 사이의 거리)이 최대가 되도록 하는 결정 경계를 찾는다. 결정 경계와 가장 가까운 데이터 포인트들을 Support Vector 이라 하며, 이 점들이 초평면의 위치를 결정한다. (다른 점들은 계산에 필요가 없음)
데이터가 2차원일때의 간단한 예시를 살펴보자.

파란점과(-) 빨간점으로(+) 표시되는 두 클래스가 있다. SVM은 이 두 클래스를 구분짓는 결정경계를 찾는것이 목적이고, 앞서 설명한 초평면 결정에 관여하는 Support Vector 들은 위 그림에서 점선 위에 존재하는 데이터 포인트들이다. 초평면과 수직한 벡터 𝑤⃗ 를 생각해보자. 어떠한 데이터포인트 u 에 대하여 u 가 초평면을 기준으로 어떤쪽에 위치하는지 (어떤 클래스로 분류되는지) 여부는 다음과 같은 수식으로 생각해볼 수 있다.

이때, SVM에서는 마진이 확보되어야 하므로 다음과 같이 쓸 수 있다.
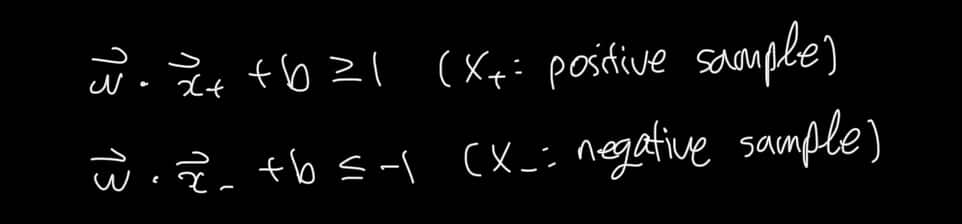
이번에는 수식을 간단화하기 위해 y 값을 식에 곱해보자.
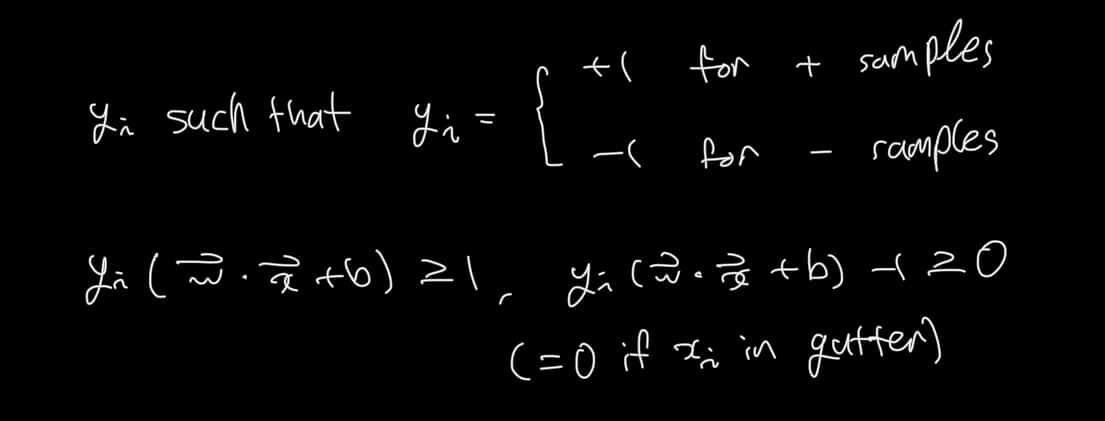
다시 처음으로 돌아와서, 우리는 마진이 최대가 되기를 원한다. 만약 초평면과 수직한 Unit Vector가 있고 다른 클래스에 속하는 Support Vector를 각각 하나씩 안다면 점선 사이의 너비를 구할 수 있다.
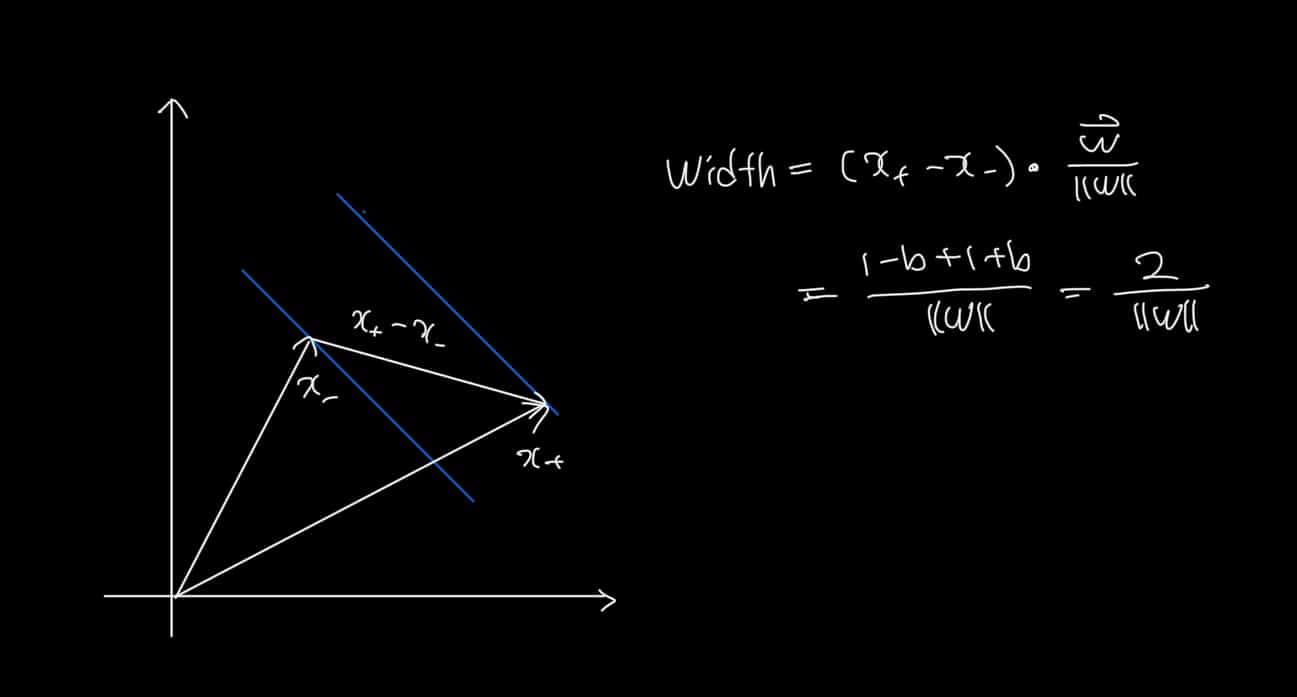
Width 값을 Maximize 하는 것은 결국 1/2*|| 𝑤⃗ ||^2 값을 Minimize 하는 문제로 치환할 수 있다.
이제 여기에 라그랑주 승수법을 적용해보자.
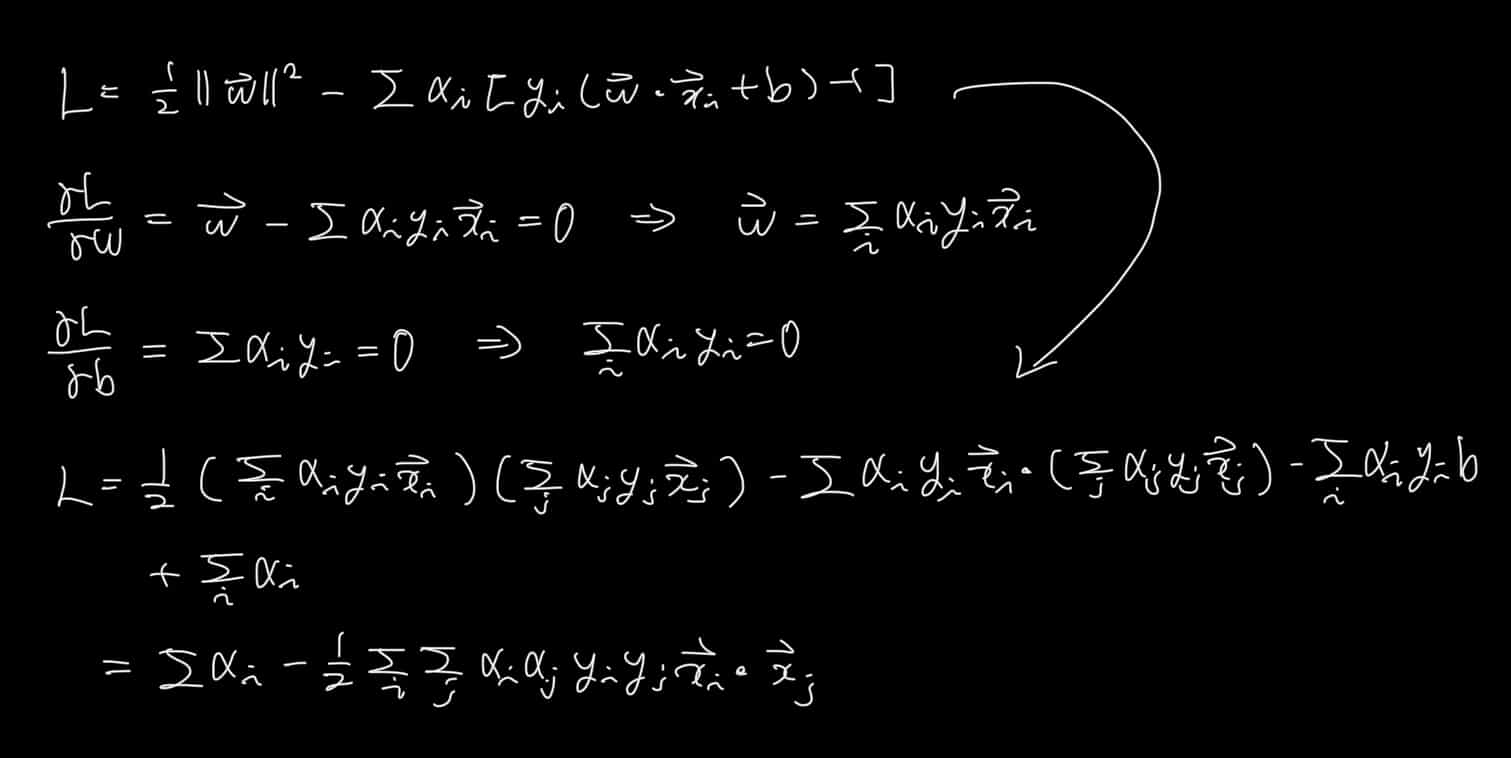
위의 식들을 통해서 알아낼 수 있는 것은
1) 초평면은 Support Vector 들의 선형 결합으로 나타낼 수 있다.
2) dual form 을 보면 SVM 모델 학습에는 데이터가 오직 내적 형태로만 존재한다.
참고로 SVM 모델 학습시에는 모든 데이터의 내적값이 필요하지만 추론시에는 예측하고 싶은 데이터와 Support Vector들 간의 내적값만 사용된다.
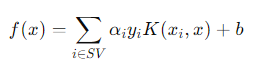
(K는 kernel functoin 이다. 밑에서 설명할 것)
우선 여기까지 이해한 후에 Soft Margin SVM으로 넘어가보자!
모든 데이터가 처음에 본 예시처럼 결정 경게를 기준으로 분류 가능하다면 좋겠지만, 현실에 적용할 때는 완벽하게 분리되지 못하는 경우가 많다. 때문에 결정 경계를 기준으로 어느 수준까지는 오차를 허용하는 것이 Soft Margin SVM 이다.

ξᵢ (slack variable): 오분류 정도
C: 마진과 오분류의 Tradeoff. C값이 커지면 오분류를 강하게 제한하는 대신 과적합 위험이 생기고 C값이 작아지면 오분류를 더 허용하는 대신 일반화 성능이 향상된다.
현실 세계의 데이터는 선형으로 아예 분리가 안되는 경우도 흔히 존재한다. 이럴때는 데이터를 고차원으로 매핑한 후 선형으로 분리하는 방법이 있다.
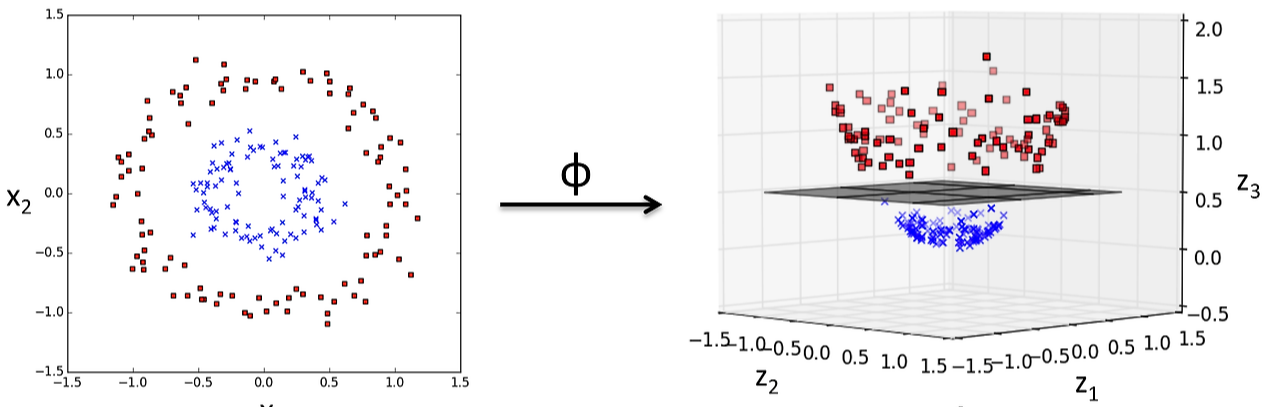
여기서 직접 모든 데이터를 고차원으로 매핑하고 내적을 하면 지나치게 계산량이 증가한다. SVM의 dual form 에서는 데이터가 오직 내적 형태로만 등장하기 때문에 우리는 내적값만 계산할 수 있으면 된다. 이 내적값을 직접 계산하지 않고 커널 함수로 대신 계산하는 것을 Kernel Trick 이라고 한다.

대표적인 커널로는 Polynomial Kernel, RBF Kernel, Sigmoid Kernel 등이 있다.
- Polynomial Kernel

c: 상수항, d: 차수
d 값이 커질수록 모델의 복잡도가 증가한다.
- RBF Kernel

감마값이 커질수록 국소적 분류를 하고 과적합이 된다.
각 Support Vector를 중심으로 부드러운 종 모양을 만들고, 이것들이 겹쳐 경계를 형성한다.
직관적으로 수식에 대해 생각해보면 데이터포인트 x가 Support Vector
- Sigmoid Kernel

마지막으로 공부에 도움이 된 자료들이다.